1. What MapReduce is built for
MapReduce is the core offline batch-processing framework in the Hadoop ecosystem. Its job is to process data at very large scale—TB to PB level—by spreading work across hundreds or even thousands of machines.
What made it so important is not just distributed execution, but the fact that many difficult concerns are handled by the framework itself:
- distributed computation
- automatic fault tolerance
- automatic task scheduling
- automatic data splitting
- horizontal scalability
Even though Spark has long surpassed MapReduce in both speed and development efficiency, MapReduce still remains in production in many companies. More importantly, its design ideas continue to shape later systems such as Spark and Flink.
2. The core idea: divide, distribute, aggregate
At its heart, MapReduce is an implementation of divide and conquer.
A large computation is broken into many smaller tasks that can run in parallel:
- Map: transform input into a collection of key → value pairs
- Shuffle: group and redistribute records by key
- Reduce: aggregate the values belonging to the same key
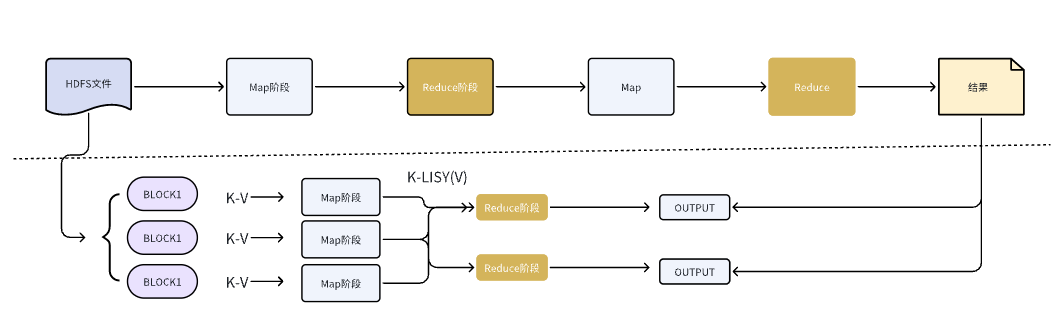
The high-level pipeline is:
Map → Shuffle → Reduce → Output
And in real data workflows, one round is often not enough:
MR → MR → MR → MR ...
This is also why Spark's RDD model is often seen as an evolution of the same idea. It keeps the distributed transformation mindset, but improves the execution model through:
- less reliance on disk
- pipelined processing
- DAG scheduling
3. Why MapReduce mattered—and why it was overtaken
Strengths
MapReduce became dominant for good reasons:
- it is well suited to massive data processing at TB–PB scale
- its programming model is simple: mainly
MapandReduce - it handles failures automatically, rerunning work when a node goes down
- it integrates deeply with HDFS, enabling data-local execution
- it scales out naturally by adding more machines
- it hides tedious details such as task scheduling, data slicing, and retry logic
Limitations
Its weaknesses are also exactly why newer engines replaced it for many workloads:
- heavy disk I/O
- expensive shuffle operations
- poor real-time behavior and high latency
- long chains of MR jobs lead to low overall efficiency
- weak fit for iterative workloads such as machine learning and graph computation
4. WordCount: the simplest complete MapReduce example
WordCount is the classic introductory case because it goes through the entire MapReduce pipeline without hiding any of the essentials.
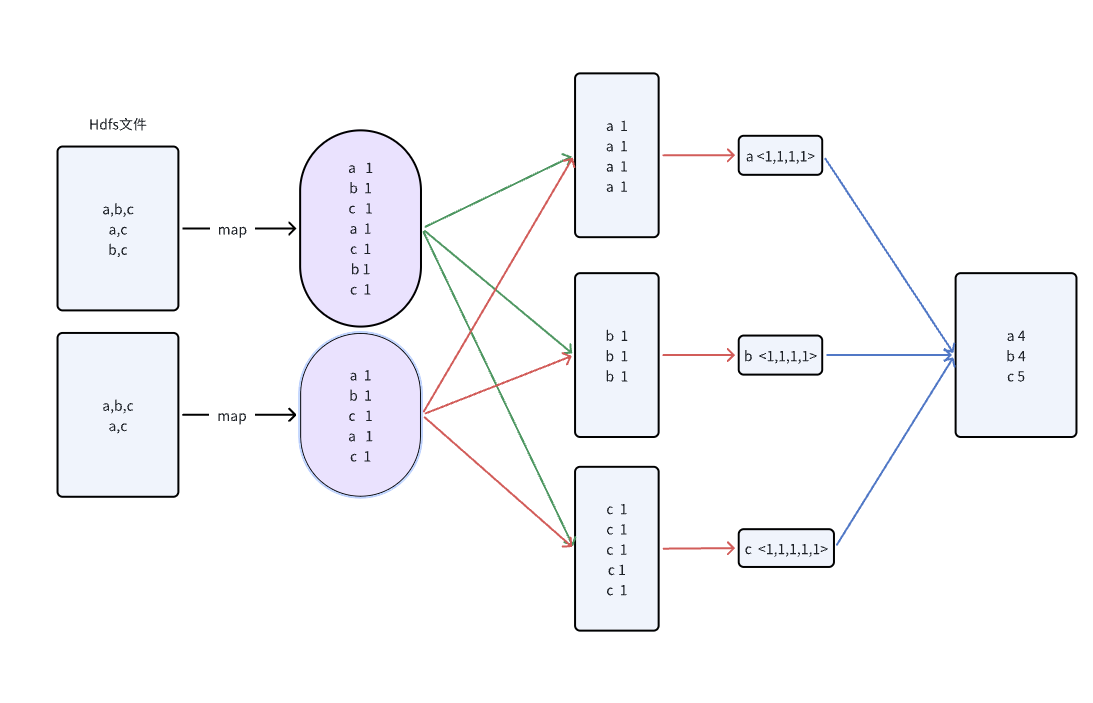
Input stored in HDFS:
a b c
a c b
a
Map output
The Map phase emits one record per word occurrence:
(a,1)
(b,1)
(c,1)
(a,1)
...
After Shuffle
Records are regrouped by key:
a → <1,1,1,1>
b → <1,1>
c → <1,1,1,1,1>
Reduce result
The Reduce phase aggregates each value list:
a → 4
b → 2
c → 5
The example is simple, but it captures the exact logic MapReduce depends on: emit, regroup, and aggregate.
5. The programming model: Map, Reduce, and the job driver
Map stage: parse input and emit key-value pairs
A mapper typically does the following:
- read the data in its assigned split
- parse it according to format, such as lines, JSON, or CSV
- output
<key, value>records - write those records into the shuffle buffer, which is implemented as a circular buffer
One practical issue is that Map output should not become too large. If it does, the system spills to disk too frequently, which hurts performance.
Reduce stage: aggregate values for the same key
The reducer receives data in the form:
key → [value1, value2, value3 ...]
Typical Reduce-side work includes:
- summation
- counting
- max/min computation
- grouped aggregation
- joins, especially Reduce Join
- deduplication with Distinct-style logic
The final Reduce output is written back to HDFS.
Serialization with Writable
Because MapReduce moves data across machines, its intermediate data format must support efficient cross-node transmission. Hadoop therefore uses Writable, its own serialization mechanism.
Compared with Java's default Serializable, Writable is much lighter and significantly more efficient.
Common Writable types include:
Textfor stringsIntWritableLongWritableBooleanWritableArrayWritable
Writable exists for a reason: Map → Shuffle → Reduce moves huge amounts of data at high frequency, so compact and efficient serialization matters.
6. How InputSplit determines mapper work
InputSplit defines the range of data processed by each MapTask.
A few rules are essential:
- by default, splits align with HDFS blocks, typically 128 MB
- each split corresponds to one
MapTask - splits are calculated by the client, not by the DataNode
- many small files can be combined with
CombineInputFormat
The core split-sizing logic is often summarized as:
splitSize = max(minSize, min(goalSize, blockSize))
This is why large numbers of small files are such a problem in Hadoop:
- too many
MapTasks are created - job startup becomes slower
- overall efficiency drops sharply
7. Shuffle: the soul of MapReduce and its biggest bottleneck
Shuffle is the most important and most complicated part of MapReduce.
It is responsible for:
- partitioning
- sorting
- merging
- fetching data across the network
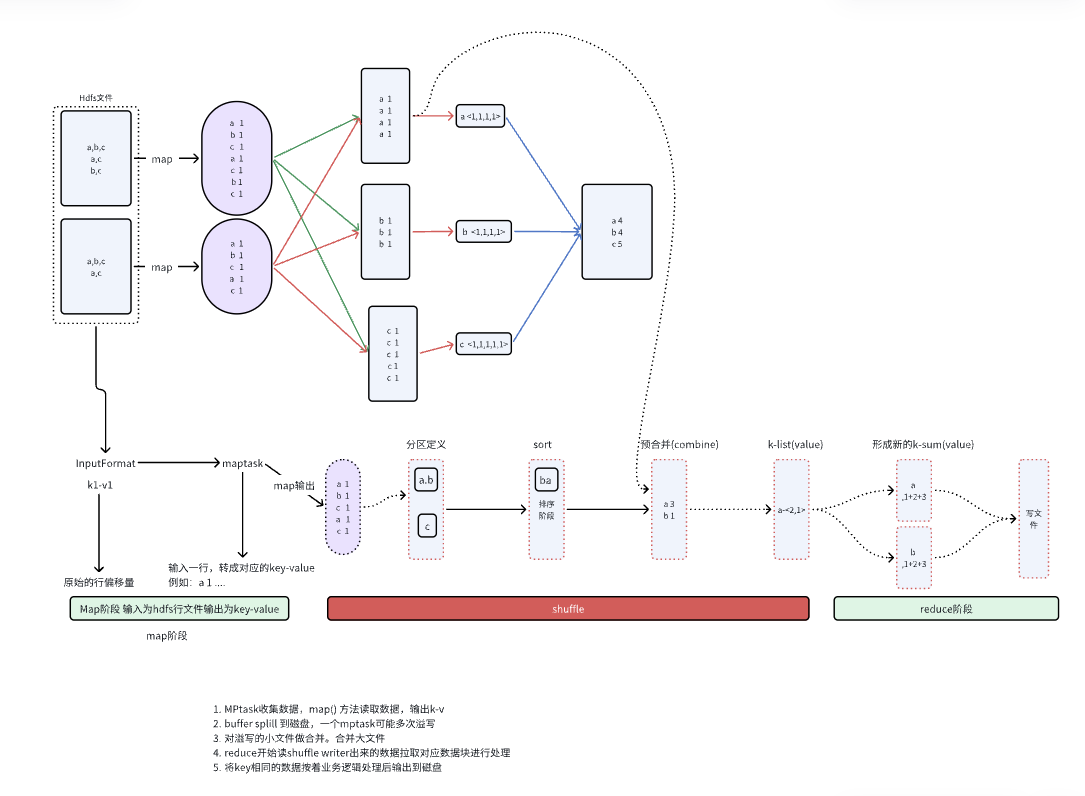
Shuffle determines whether:
- each reducer receives the correct data for its keys
- the entire job runs quickly or slowly
- data skew turns into a serious runtime problem
In practice, Shuffle is the make-or-break stage for MR performance.
8. What happens during Map-side Shuffle
Map output is first written into a circular buffer.
When the buffer reaches its threshold—commonly 80%—the framework triggers a spill to disk.
Spill process
Each spill performs several operations:
- sort by key
- group by partition
- write to disk and generate a spill file
A single MapTask often spills multiple times.
Map-side merge
Those spill files are then merged into one final output file for that mapper:
- each partition becomes a file segment
- data within each partition remains ordered, which prepares it for later Reduce-side merging
This is one reason MapReduce incurs so much disk I/O before reducers even begin real aggregation.
9. What happens during Reduce-side Shuffle
Each ReduceTask must fetch the data that belongs to its partition from all completed MapTasks.
The process is roughly:
- use the partition number to fetch remote Map output through HTTP
- perform merge sort across many Map output files
- produce one large file ordered by key
- pass that ordered data into the Reduce function for aggregation
This stage is especially prone to three problems:
- network bottlenecks
- data skew
- reducers waiting a very long time on slow partitions or slow transfers
Because every reducer depends on outputs from many mappers, inefficiency here can hold back the entire job.
10. The full Shuffle path
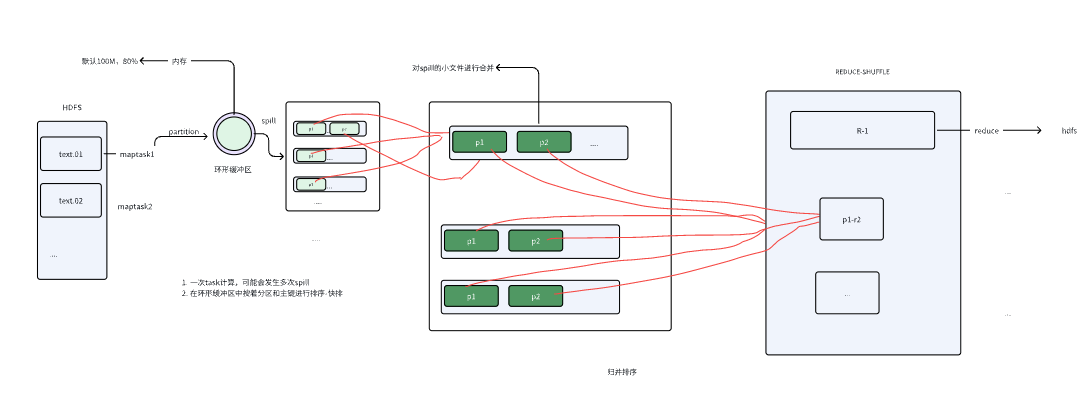
Two disk-write moments stand out:
- Map spill
- Map merge
And sorting happens repeatedly:
- quicksort during spill
- multi-way merge during merge
- another merge on the Reduce side
That is why Shuffle is usually the slowest part of a MapReduce job.
11. Compression as a practical optimization
Compression is a key performance lever in MapReduce.
Why compress intermediate or input data?
- to reduce the amount of data transferred from Map to Reduce, easing network pressure
- to reduce disk writes, especially spill size
- to improve overall Shuffle speed
A simple rule of thumb:
- for I/O-heavy workloads, favor a stronger compression ratio
- for compute-heavy workloads, lighter compression may be better
12. A concise way to understand MapReduce
In one sentence, MapReduce is a distributed computing framework based on divide and conquer: it uses Map to produce key-value pairs, Shuffle to partition and sort them, and Reduce to aggregate them into final large-scale batch results.
If you want to judge whether someone truly understands MR, these are the questions that matter most:
- the complete execution flow of Map and Reduce
- the difference between
InputSplitand HDFS block - the internal mechanics of Shuffle
- when spill occurs
- why Shuffle is the main performance bottleneck
- how a Combiner can reduce network transfer
- how the partitioner affects reducer distribution and count