Overview
In an HDFS high-availability setup, the component sitting between the Active NameNode and the Standby NameNode is the JournalNode. The green area between those two nodes is the JournalNode layer, and it does not have to be limited to a single instance. Its role is similar to a shared NFS-style storage system: the Active NameNode writes edit log data into it, and the Standby NameNode reads those logs back to stay synchronized.
From the architecture perspective, JournalNode occupies the position shown below:
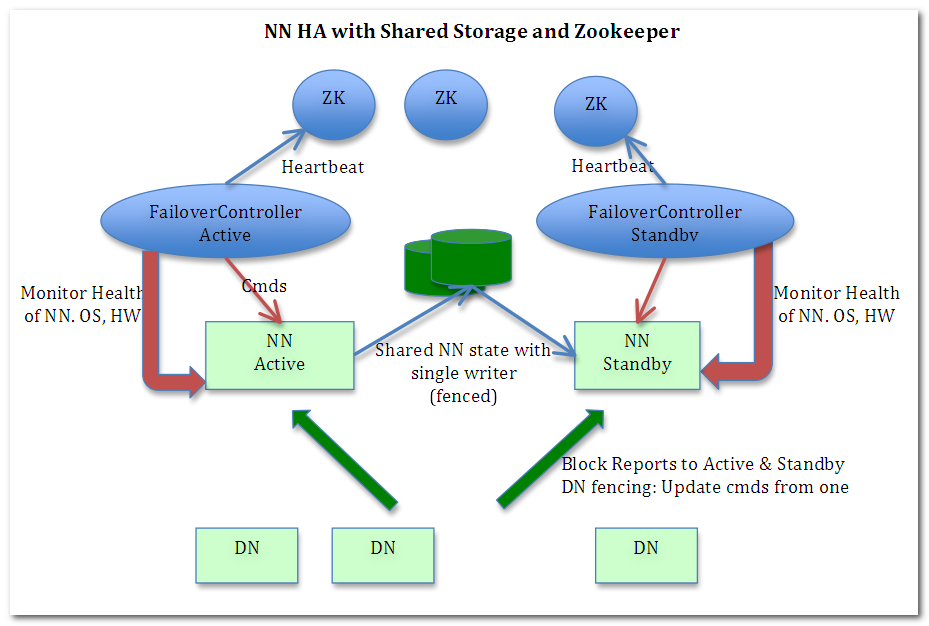
What JournalNode is responsible for
Looking at the code, the core responsibilities of a JournalNode can be grouped into three parts:
- starting the JournalNode service
- reading and writing edit logs
- synchronizing edit log data across JournalNodes
The startup path is the clearest part in the code shown here, and it reveals the two service endpoints that JournalNode exposes.
Startup entry
The startup entry class is JournalNode.java, and execution begins in main. During startup, two major components are brought up:
JournalNodeHttpServer, which provides the HTTP service used when reading edit logsJournalNodeRpcServer, which provides the RPC service used primarily for writing edit logs under the current protocol
JournalNodeHttpServer
This class is the HTTP side of the JournalNode. The key step during initialization is registering the servlet responsible for serving journal edits: GetJournalEditServlet.
httpServer.addInternalServlet("getJournal", "/getJournal", GetJournalEditServlet.class, true);
httpServer.start();
The main purpose here is straightforward: edit log reads. There is no extra complexity highlighted in this part.
JournalNodeRpcServer
This class is the RPC side of the JournalNode. Its central task is bringing up the RPC server itself. The server is initialized through the following code:
this.server = new RPC.Builder(confCopy)
.setProtocol(QJournalProtocolPB.class)
.setInstance(service)
.setBindAddress(bindHost)
.setPort(addr.getPort())
.setNumHandlers(this.handlerCount)
.setVerbose(false)
.build();
What matters most here is the protocol definition it serves. The RPC contract is described by QJournalProtocol.java, which contains the operations used to manage journal state, write log segments, query edit logs, and handle recovery-related behavior.
A representative portion of that interface is shown below:
public interface QJournalProtocol {
public static final long versionID = 1L;
boolean isFormatted(String journalId,
String nameServiceId) throws IOException;
GetJournalStateResponseProto getJournalState(String journalId,
String nameServiceId)
throws IOException;
void format(String journalId, String nameServiceId,
NamespaceInfo nsInfo, boolean force) throws IOException;
NewEpochResponseProto newEpoch(String journalId,
String nameServiceId,
NamespaceInfo nsInfo,
long epoch) throws IOException;
public void journal(RequestInfo reqInfo,
long segmentTxId,
long firstTxnId,
int numTxns,
byte[] records) throws IOException;
public void heartbeat(RequestInfo reqInfo) throws IOException;
public void startLogSegment(RequestInfo reqInfo,
long txid, int layoutVersion) throws IOException;
public void finalizeLogSegment(RequestInfo reqInfo,
long startTxId, long endTxId) throws IOException;
public void purgeLogsOlderThan(RequestInfo requestInfo, long minTxIdToKeep)
throws IOException;
GetEditLogManifestResponseProto getEditLogManifest(String jid,
String nameServiceId,
long sinceTxId,
boolean inProgressOk)
throws IOException;
GetJournaledEditsResponseProto getJournaledEdits(String jid,
String nameServiceId, long sinceTxId, int maxTxns) throws IOException;
public PrepareRecoveryResponseProto prepareRecovery(RequestInfo reqInfo,
long segmentTxId) throws IOException;
public void acceptRecovery(RequestInfo reqInfo,
SegmentStateProto stateToAccept, URL fromUrl) throws IOException;
void doPreUpgrade(String journalId) throws IOException;
public void doUpgrade(String journalId, StorageInfo sInfo) throws IOException;
void doFinalize(String journalId,
String nameServiceid) throws IOException;
Boolean canRollBack(String journalId, String nameServiceid,
StorageInfo storage, StorageInfo prevStorage,
int targetLayoutVersion) throws IOException;
void doRollback(String journalId,
String nameServiceid) throws IOException;
@Idempotent
void discardSegments(String journalId,
String nameServiceId,
long startTxId)
throws IOException;
Long getJournalCTime(String journalId,
String nameServiceId) throws IOException;
}
How to read the protocol at a glance
Even without going deeper into each implementation, the interface already shows the shape of JournalNode’s responsibilities.
- State management:
isFormatted,getJournalState,format,getJournalCTime - Epoch and coordination:
newEpoch,heartbeat - Edit log writing:
journal,startLogSegment,finalizeLogSegment - Log retention and lookup:
purgeLogsOlderThan,getEditLogManifest,getJournaledEdits,discardSegments - Recovery flow:
prepareRecovery,acceptRecovery - Upgrade and rollback handling:
doPreUpgrade,doUpgrade,doFinalize,canRollBack,doRollback
This matches the JournalNode’s role in HA quite closely. It is not just passive storage for edit logs; it also participates in segment lifecycle management, synchronization support, and recovery coordination.
Edit log reads and writes
At a high level, the split between the two services is clear:
- the HTTP service is used for reading edit logs
- the RPC service is used mainly for writing edit logs and coordinating journal operations
That design also explains the relation between the Active and Standby NameNodes. The Active side writes edit log records into JournalNode, while the Standby side reads them back to keep metadata changes in sync.
Synchronization between JournalNodes
Another important responsibility is edit log synchronization among JournalNodes. The protocol makes this visible through operations related to manifests, fetching journaled edits, and recovery. Even from the exposed interface alone, it is clear that JournalNode is designed not only to store log data but also to support consistency and recovery across multiple nodes in the journal layer.
So if you look at JournalNode from the code structure alone, its design centers on two access paths—HTTP for reading and RPC for write/control operations—built around the edit log as the core data unit.